TicTacToeArtist: CV·로보틱스 기반 틱택토 AI
1. 🔗 프로젝트 개요 & 링크
CNC 플로터(로봇) - 틱택토 판 인식(CV) - 듀얼 제로섬 게임 에이전트(RL)를 개발해 시스템화시켰다.
2. ✨ 핵심 역량 & 문제 해결
역할: 팀원 · 강화시스터즈(24-2)
듀얼 에이전트 제로섬 게임 알고리즘 이론 강의 · 로보틱스
- minmax알고리즘부터 알파제로까지 듀얼 제로섬 게임 에이전트 이론을 공부하고 동아리원을 지도했습니다.
- 아두이노 공부를 학기 초부터 병행해 동아리원들의 CV와 AI 작업 이전에 로보틱스를 완성했습니다.
- 아두이노에서 발생하는 불안정성을 없애기 위해 C를 공부해 프로젝트에 최적화된 동작 라이브러리를 개발했습니다.
3. ⚙️ 개발 과정
- 듀얼 에이전트 개인 공부, 로보틱스 부분을 작성했습니다.
4. 📊 결과 & 성과
- 틱택토는 승리 패턴이 적기 때문에 두 번째 플레이어가 불리합니다. 알파제로를 적용한 틱택토 에이전트는 두 번째 플레이어일 때도 낮은 패배율을 보였으며 다른 고전 듀얼 제로섬 에이전트보다 높은 승률 을 보였습니다.
 |
 |
 |
 |
5. 💡 배운 점 & 다음 단계
- 싱글 에이전트와 달리 듀얼 에이전트는 상대까지 고려해 행동해야하기 때문에 사용하는 이론도, 난이도도 상이했습니다. 제로섬 게임 플레이어 이론이 어떻게 발전되어 왔고, 강화학습에서 어떻게 구현되었는지 배우는 과정이 새로웠습니다.
- 전체 구조를 짤 때는 어렵지 않을 거라 생각하고 호기롭게 시작한 프로젝트였습니다. 하지만 로보틱스에 대한 지식이 아예 없어 아주 단순한 현상이라도 문제를 명확히 규정하는 것부터가 많은 시간이 소요됐습니다. 문제를 인지하는 것부터가 해결의 시발점이라는 걸 알게 되었습니다.
TicTacToeArtist: End-to-End AI for TicTacToe with Vision and Robotics
1. 🔗 Overview & Links
Built an end-to-end loop that blends CNC plotter robotics, TicTacToe board perception, and dual zero-sum reinforcement learning agents.
2. ✨ Core Strengths & Problem Solving
Role: Team Member
Led dual-agent zero-sum algorithm sessions and engineered the robotics stack
- Mentored club members through the progression from Minimax/MCTS to AlphaZero, distilling the theory into practical agent implementations.
- Completed the robotics layer early so teammates could focus on CV and AI, integrating hardware, firmware, and calibration.
- Eliminated Arduino instability by authoring a C/C++ motion library tailored to the CNC plotter’s mechanics.
3. ⚙️ Development Process
- Authored the dual-agent research notes and implemented the robotics subsystem.
01
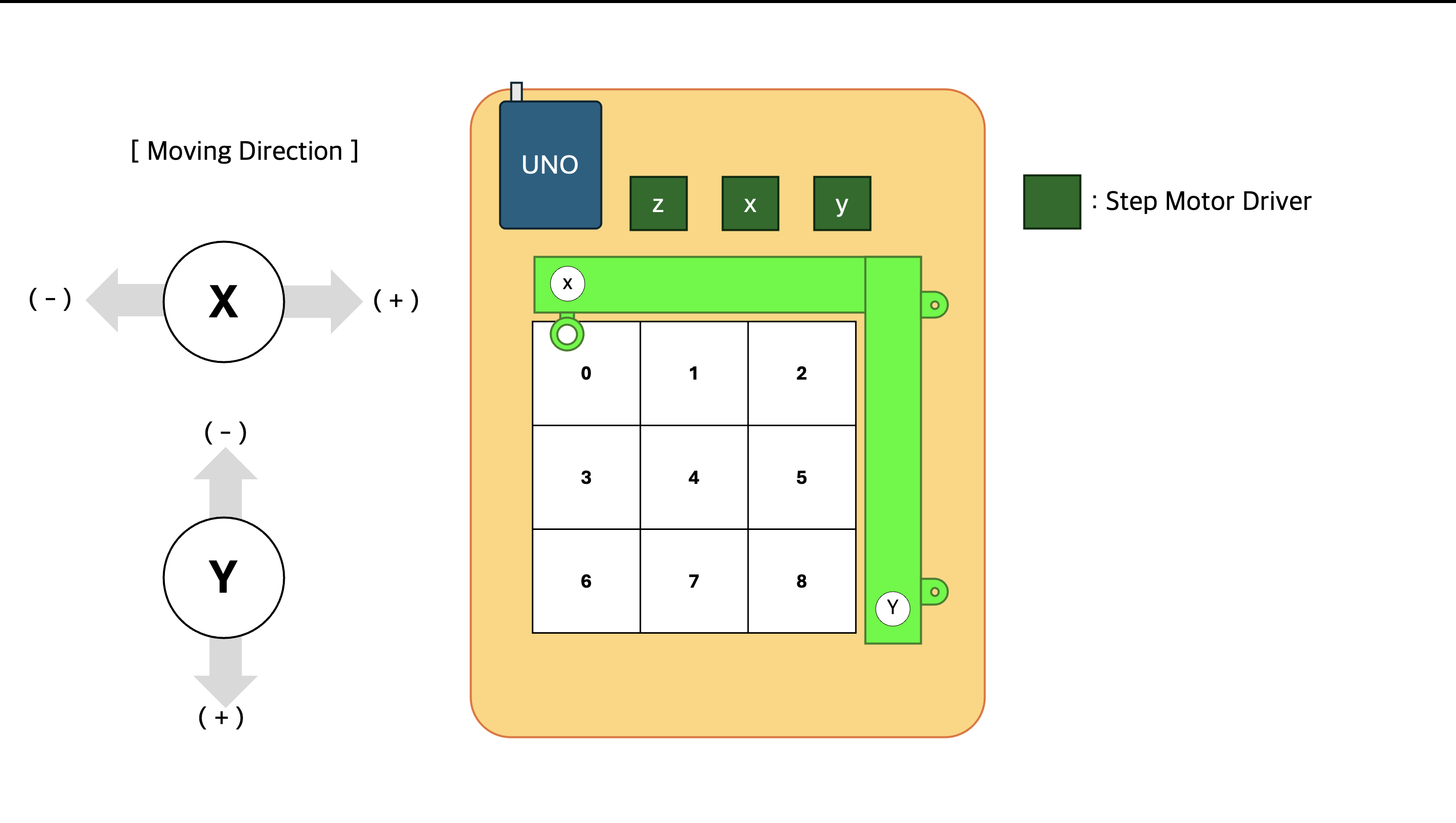
[TicTacToe/01] Building the CNC Plotter
How we constructed a drawing robot so the AI could interact with humans in the physical world.
02
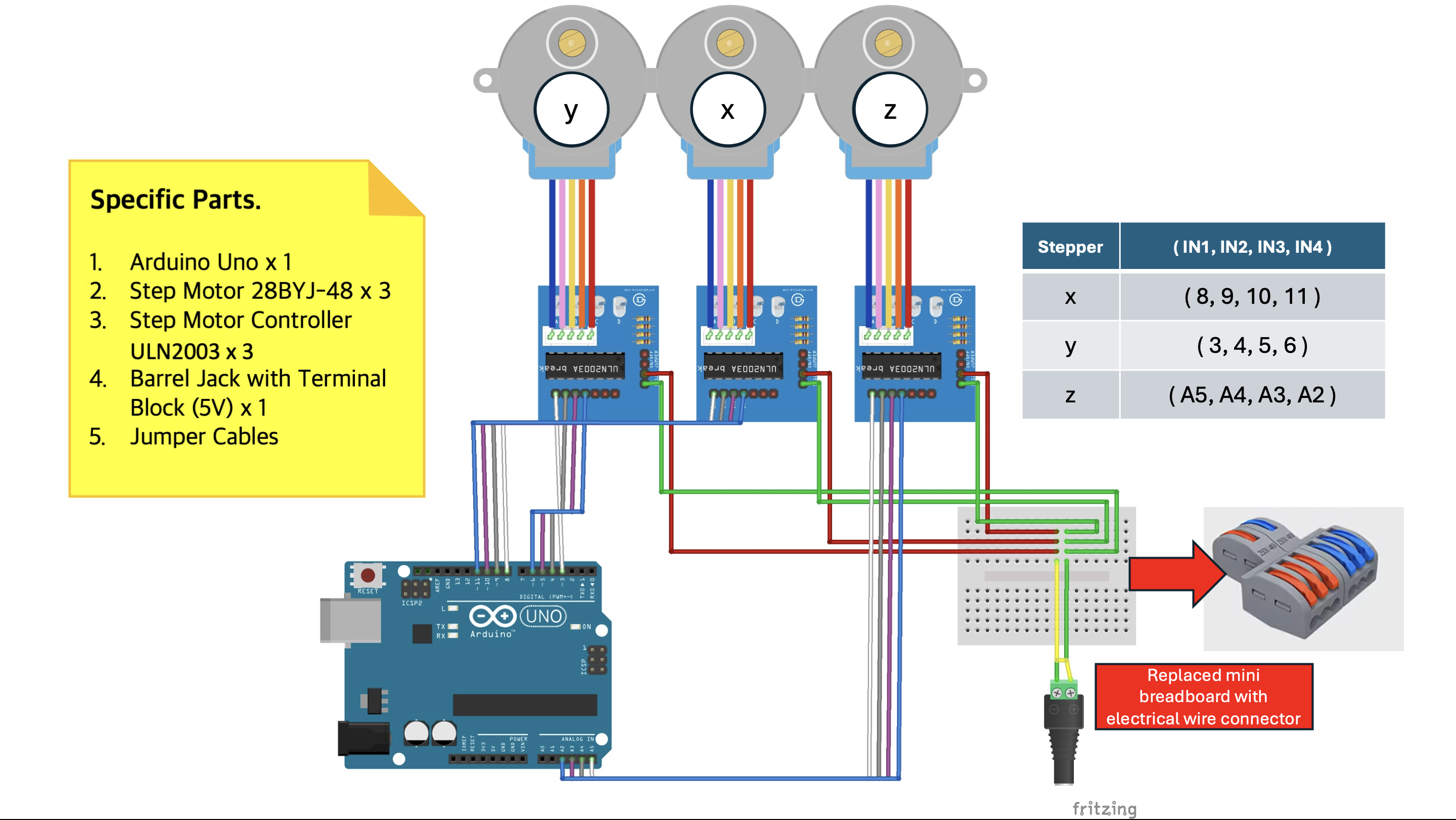
[TicTacToe/02] Controlling the CNC Plotter
Implemented a C++ library to drive the plotter precisely for turn-by-turn play.
4. 📊 Results & Outcomes
- Because TicTacToe offers few winning lines, the second player is typically disadvantaged. The AlphaZero-inspired agent maintained a low loss rate even when playing second and outperformed classical zero-sum baselines.
|
|
|
|
5. 💡 Learnings & Next Steps
- Unlike single-agent RL, dual-agent systems must reason about an opponent. Tracing how zero-sum game theory evolved and how it translates into modern RL architectures was eye-opening.
- With no prior robotics experience, even diagnosing simple mechanical issues took significant time. Recognizing and articulating the problem turned out to be the critical first step toward a fix.