PaperReview
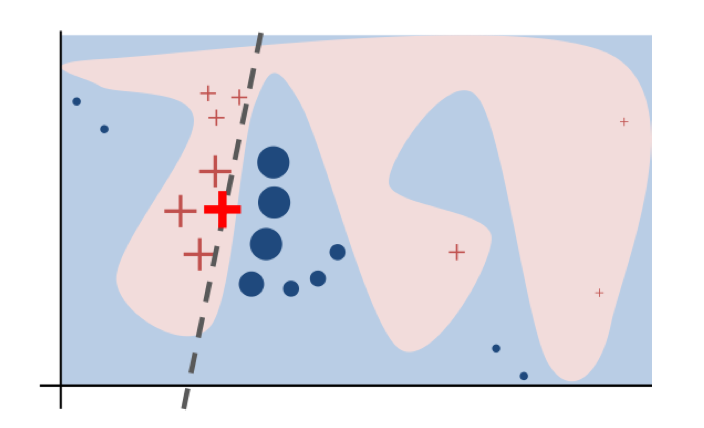
'Why Should I Trust You?: Explaining the Predictions of Any Classifier' 논문 리뷰를 바탕으로 기초 xAI 방법론 LIME을 다룬다. Handle basic xAI method LIME by reviewing 'Why Should I Trust You?: Explaining the Predictions of Any Classifier' Paper
2025. 11. 01
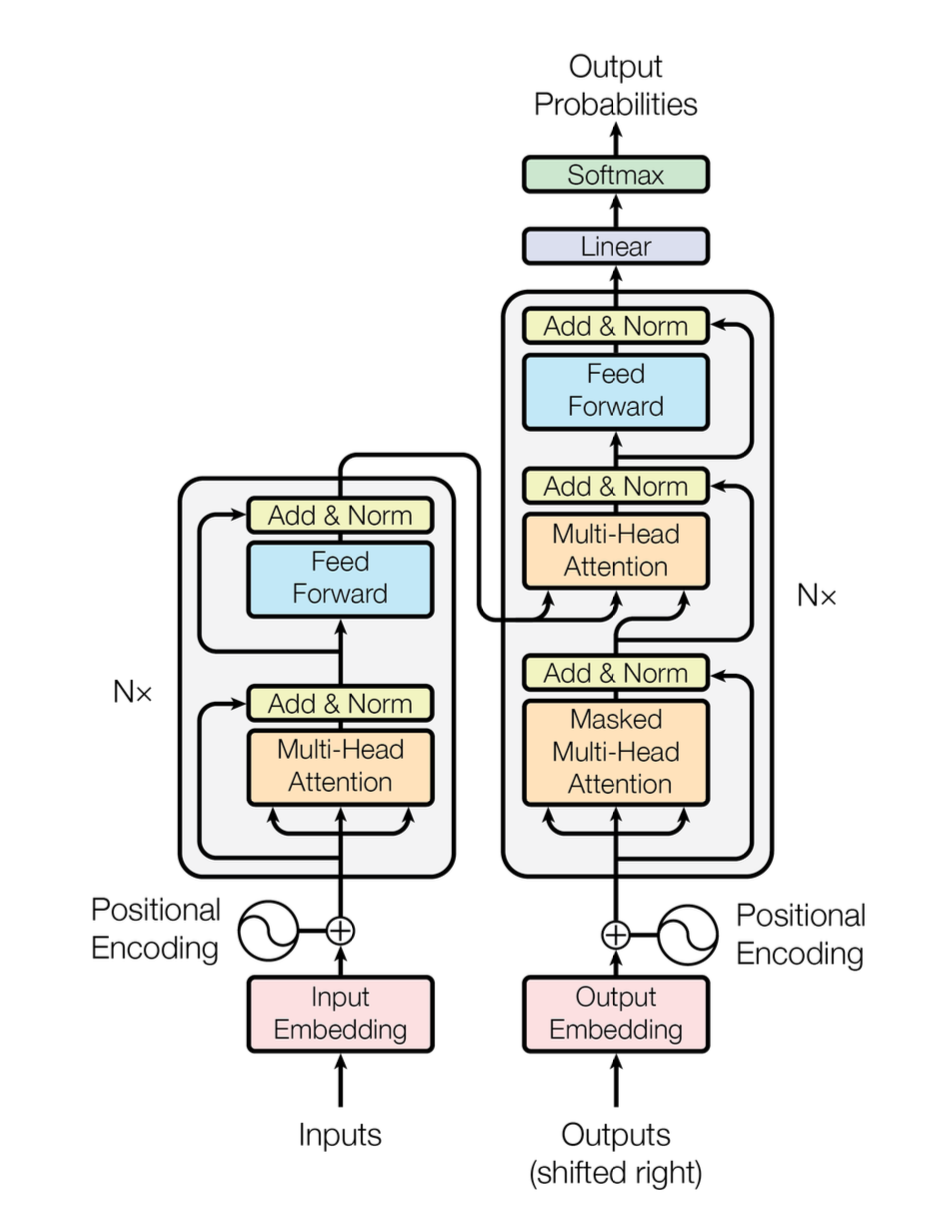
'Attention Is All You Need' 논문을 리뷰하고 Attention, LayerNorm, Positional Encoding에 관한 세부사항을 보완한다. Review 'Attention Is All You Need 'and fill details of Attention, LayerNorm, Positional Encoding.
2025. 09. 26
RL
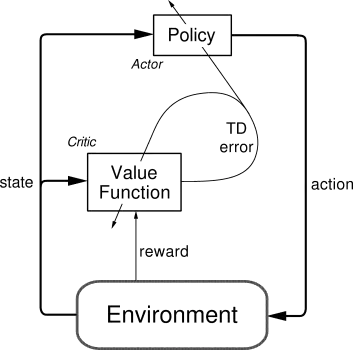
Actor Critic 개념, A2C, A3C, 코드 구현 Actor Critic Notion, A2C, A3C, Code
2025. 05. 06
RL MARL
멀티 에이전트 강화학습 기초 이론을 다룬다. Basic Notion of Multi Agent Reinforcement Learning.
2025. 05. 05
자율주행 입문용으로 유용한 DonkeyGym을 mac m1 환경에 세팅했다. Set up DonkeyGym, a useful simulator for getting started with autonomous driving, on an M1 Mac.
2025. 04. 11
TimeSeries PaperReview
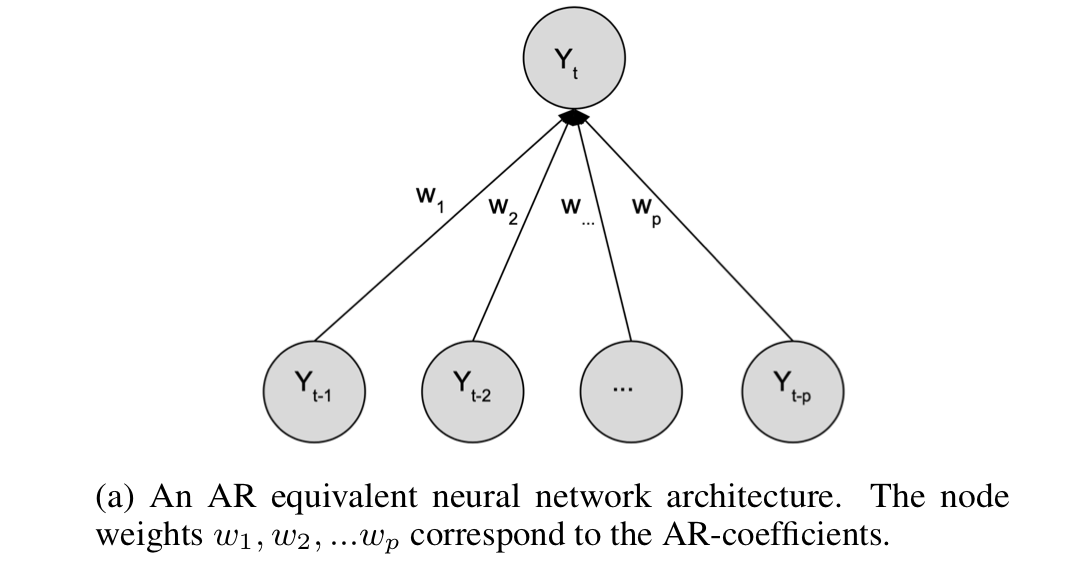
AR-Net 논문 리뷰 및 구현 Paper Review and Implementation of the AR-Net
2025. 03. 20
ML
Naive Bayes Classifer 이론 및 구현 Review and Implementation of the Naive Bayes Classifer
2025. 03. 11
RL PaperReview
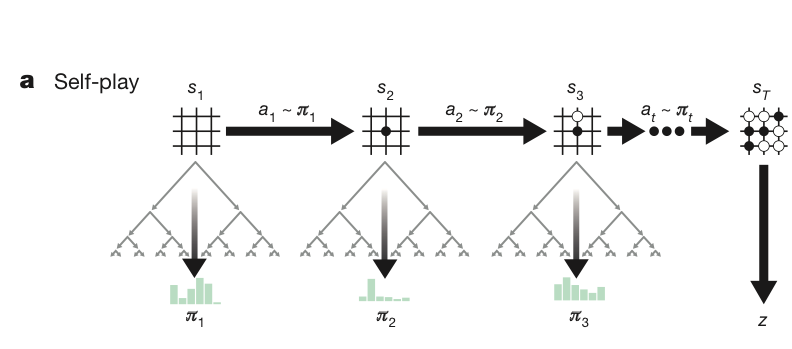
Google DeepMind가 발표한 AlphaZero 논문 리뷰 및 구현 Review and Implementation of the AlphaZero Paper Published by Google DeepMind
2025. 02. 12
Omok
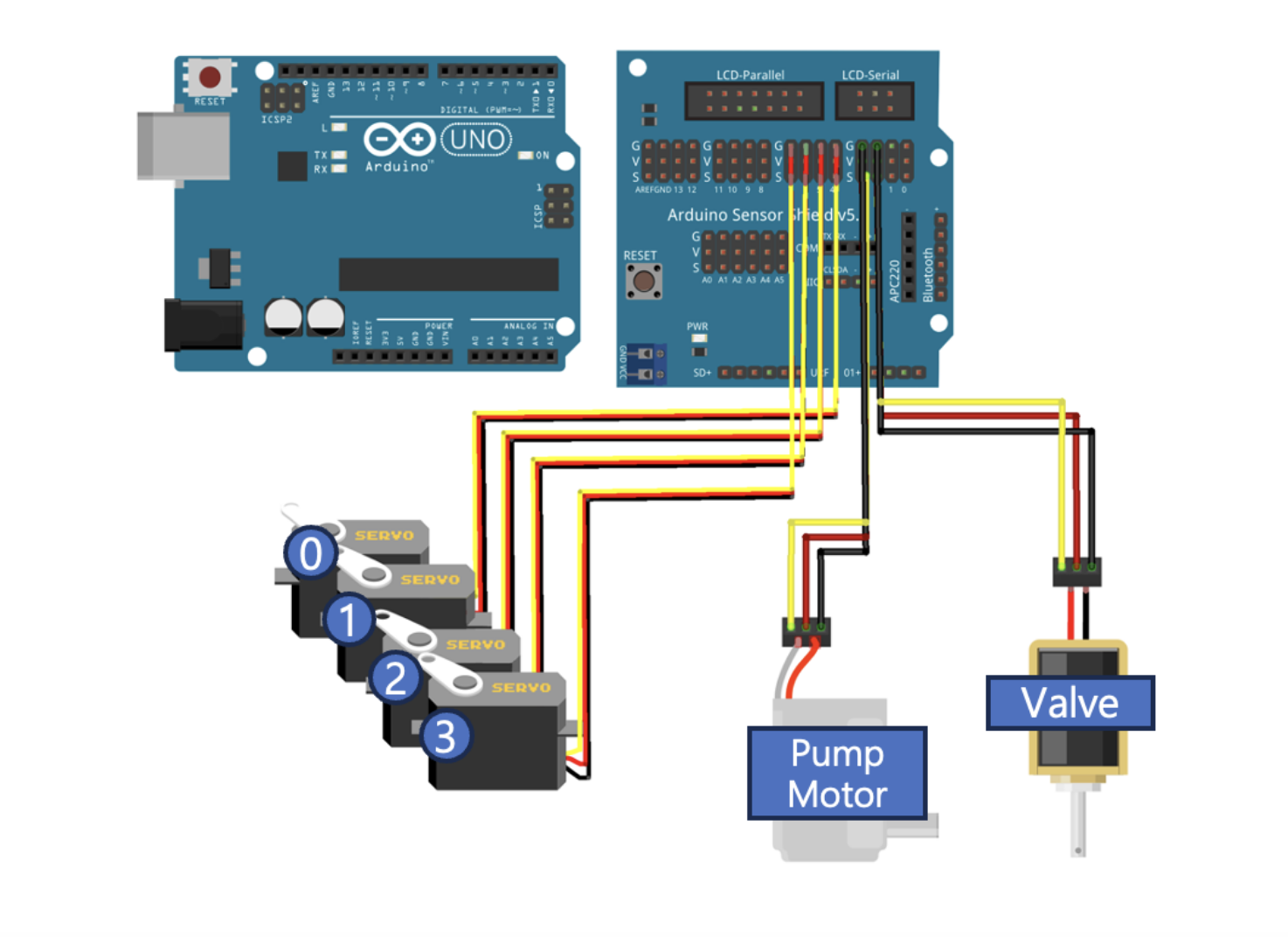
로봇팔을 제어할 때 필요한 회로를 제작했고 제어에 필요한 통신 코드를 작성했다. Built the robotic arm needed to play Gomoku and write control code.
2025. 02. 03
Cpp
기초적인 포인터와 참조 Introductory of Pointer and Reference
2024. 11. 15
C++ 클래스 기초 Introductory of C++ class
TicTacToe
C++을 이용해 CNC Plotter을 제어하는 라이브러리를 구현했다. Implemented the library to control CNC plotter by using C++.
2024. 11. 13
AI와 인간이 현실 세계에서 상호작용하게 만들고자 했다. 이를 위해 그림을 그리는 로봇인 CNC Plotter을 제작했다. To help AI and humans interact in the real world, I built CNC Plotter, a robot that draws pictures.
2024. 11. 06
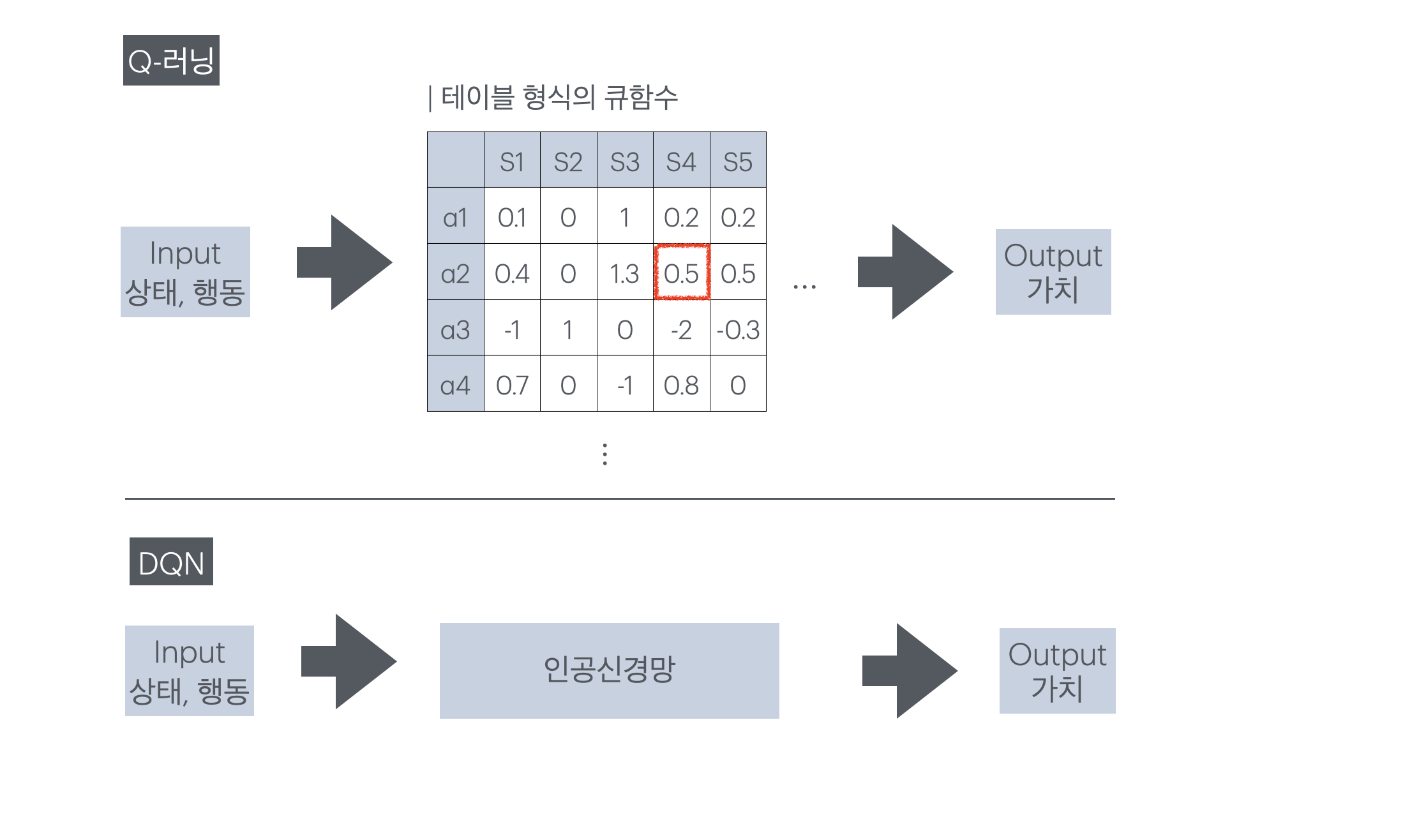
Google DeepMind가 발표한 DQN 논문 리뷰 및 구현 Review and Implementation of the DQN Paper Published by Google DeepMind
2024. 10. 13
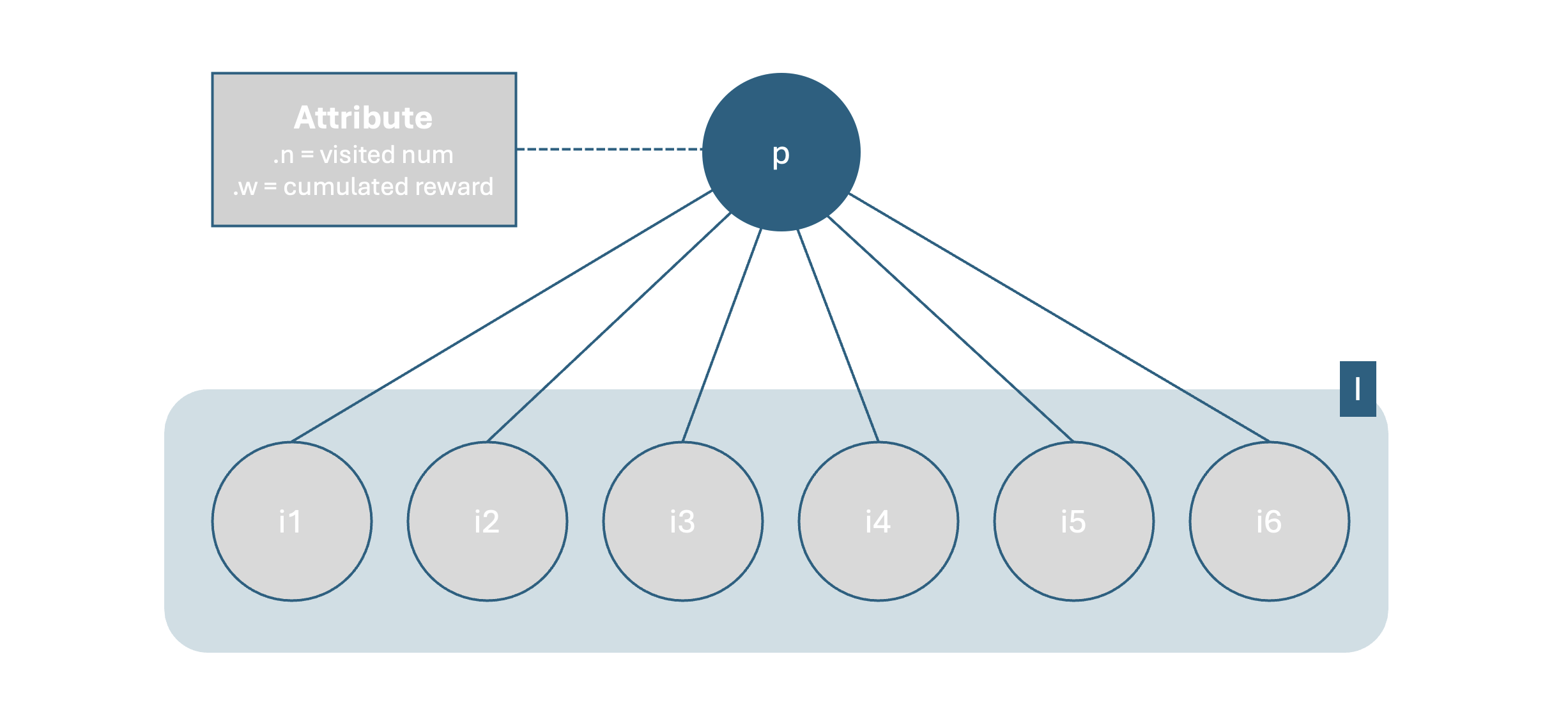
알파고, 알파제로에 사용된 몬테카를로 트리 탐색 구조 Monte Carlo tree search structure used in AlphaGo and AlphaZero
2024. 10. 07
바둑돌을 두는데 필요한 로봇팔을 조립했다. Built the robotic arm needed to play checkers.
2024. 10. 02
Minesweeper
'지뢰찾기' 플레이어 에이전트 개발 일지 'Minesweeper' Player Agent Development Log
2024. 07. 14
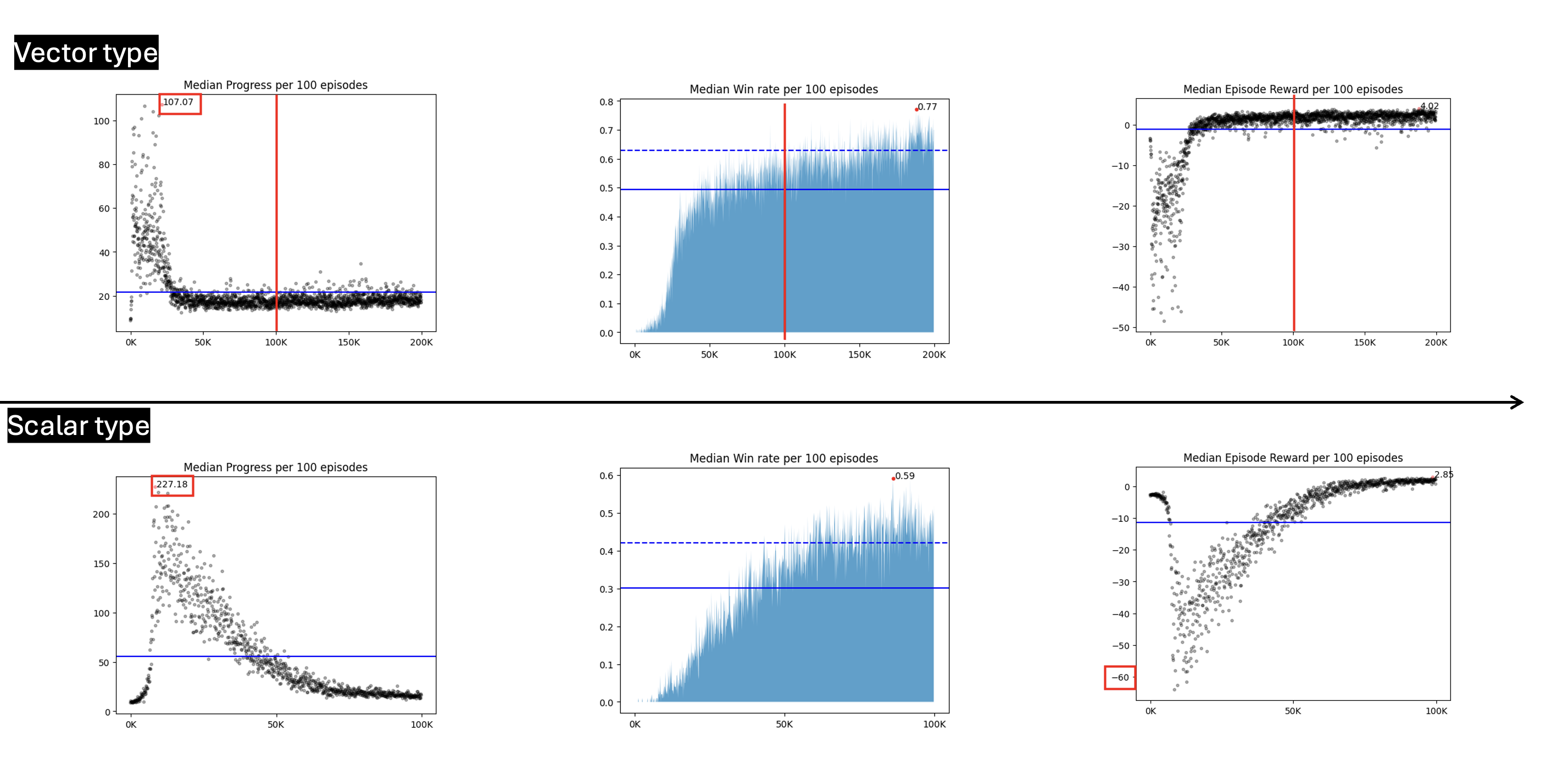
학습 중에 있었던 여러 문제를 해결하고 다양한 방법론을 적용했다. Solved multiple problems and applied different methodologies during the course of learning.
2024. 07. 13
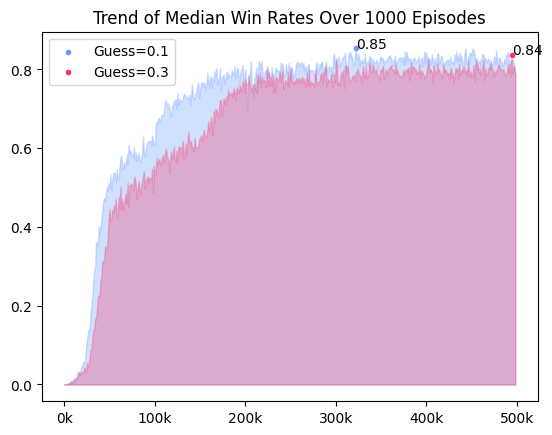
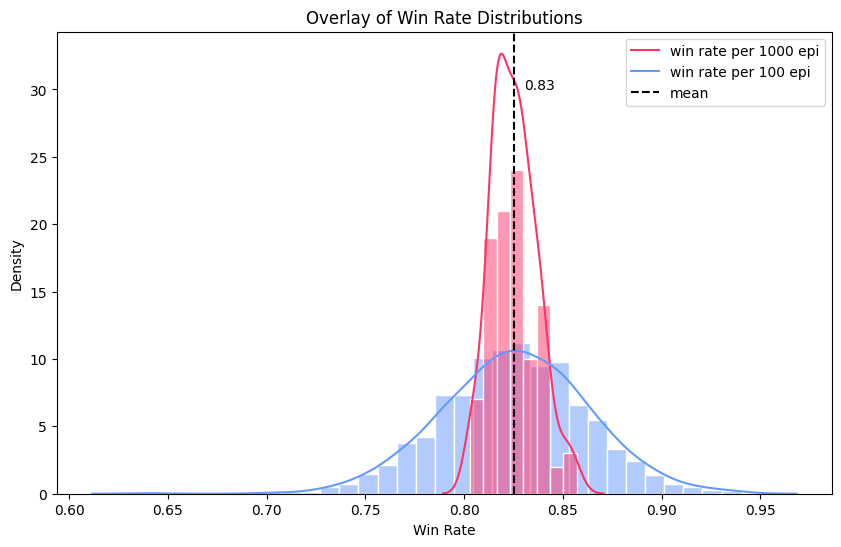
학습 동향을 알려줄 수 있는 지표를 선택하고, valid 및 test에 적절한 수의 표본량을 선택했다. Chose metrics that would tell us about learning trends, and the right number of sample sizes for valid and test.
2024. 07. 12
공간 인식에 특화된 CNN 신경망을 구현하고, 성능 향상을 위해 리플레이 메모리를 수정했으며, 두 가지 방식의 DQN 구현을 진행했다. Implemented a CNN neural network specialized for spatial recognition, modified the replay memory to improve performance, and implemented two different DQN implementations.
2024. 07. 11
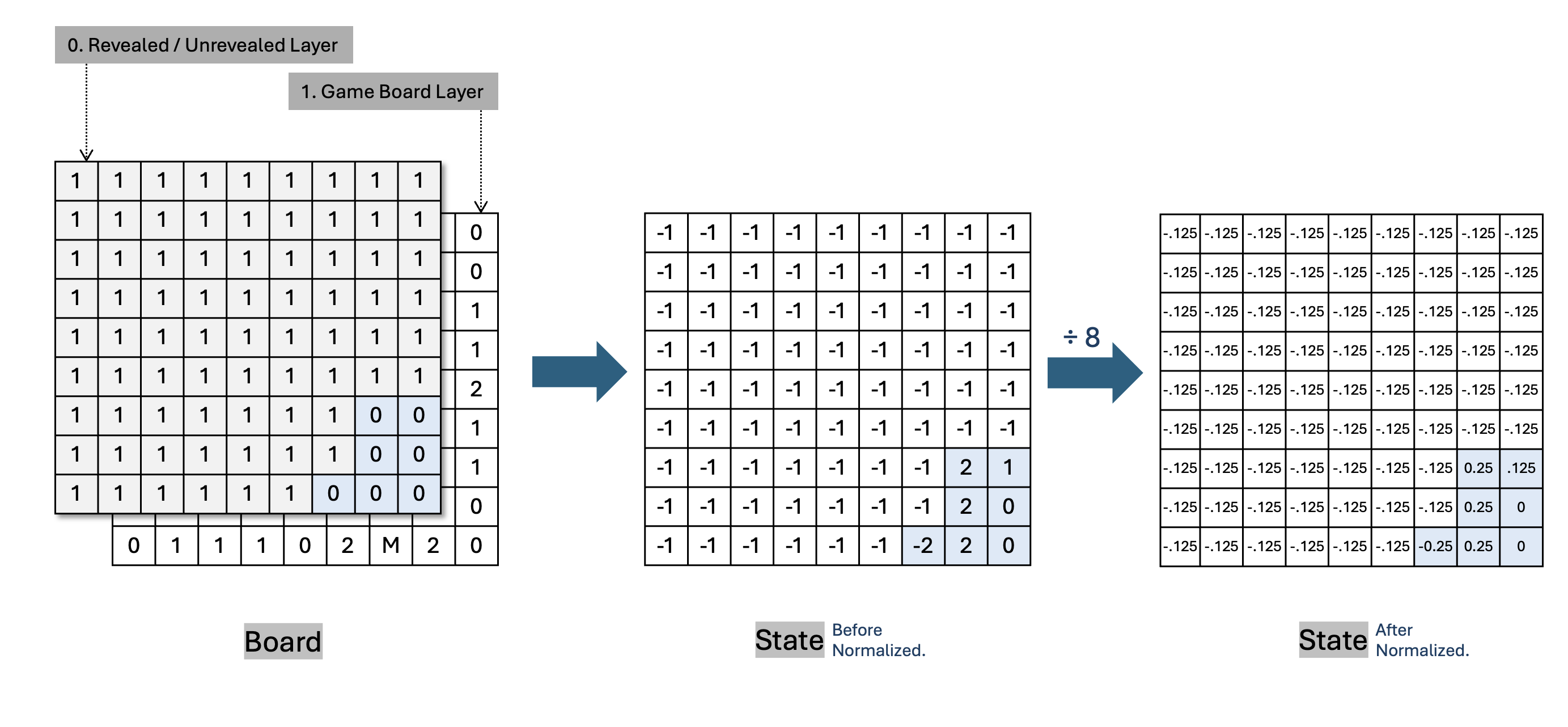
지뢰찾기 환경 구현에서 발생한 여러 문제점을 해결하고, 다양한 state를 구현했다. Resolved several issues with the Minesweeper environment implementation and implemented various states.
2024. 07. 10
창단 후 2년 동안 활동하며 작성한 글을 모았다. 대부분 기초 강화학습에 대한 발표 자료다. Collection of articles written during the leader of the club. These are mostly presentations on basic RL written in Korean.
2024. 03. 02